Benchmarking egocentric multimodal goal inference for assistive wearable agents
 Egocentric multimodal goal inference benchmark
Egocentric multimodal goal inference benchmarkAbstract
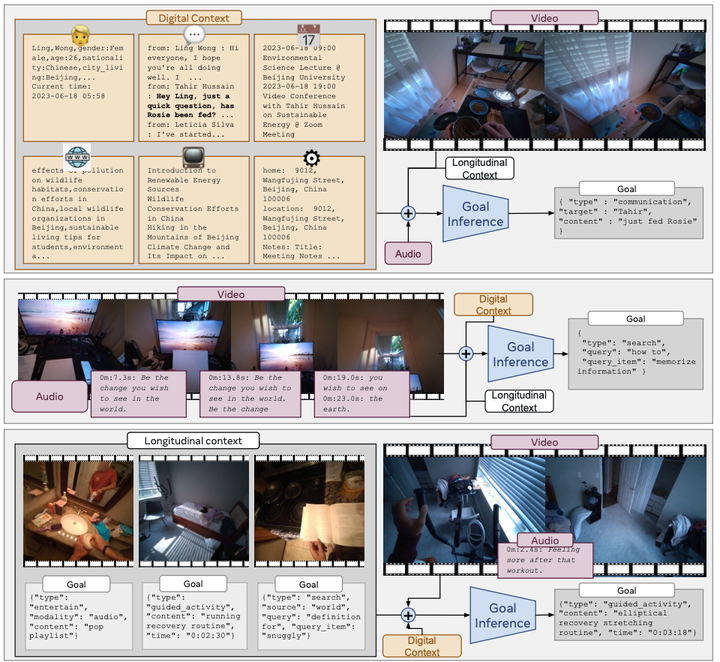
We present a benchmark for egocentric multimodal goal inference for assistive wearable agents. This benchmark evaluates the ability of AI systems to infer user goals from egocentric video, audio, and other sensor modalities in real-world scenarios. The dataset includes diverse real-world tasks and contexts, enabling evaluation of assistive agents that can proactively understand and support user intentions. This work is critical for developing next-generation wearable computers that can provide contextually-aware assistance.
Type
Publication
The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025), Datasets and Benchmarks Track, Spotlight poster